以下内容首发自公众号“小汪Waud”。 本期介绍在Linux环境下的正则表达式及grep命令。
正则表达式(Regular Expression)是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符及这些字符的特定组合,组成一个“规则字符串”,这个字符串用来表达对字符串的一种过滤逻辑。
正则表达式基本上是一种表示法,只要程序支持这种表示法,该程序就可以用来作为正则表达式的字符串处理之用。如vi、grep、awk、sed等程序支持正则表达式,所以可以使用正则表达式的特殊字符来进行字符串的处理。但例如cp、ls等命令并不支持正则表达式,所以只能用自己的通配符。 正则表达式依照 不同的严谨度 分为:基础正则表达式和扩展正则表达式。
注意! grep是一种强大的文本搜索工具,可以使用 正则表达式匹配模式 查找文件里符合条件的字符串,并打印出来。 有点类似于WORD里的查找功能。 grep支持三种正则表达式语法:Basic、Extended和perl兼容。
如果没有提供正则表达式类型,grep将搜索模式解释为基本的正则表达式。要将模式解释为扩展正则表达式,请使用-E。
GREP缩写是什么含义?它的五大功能是什么?
GREP全称是:Globally search a Regular Expression and Print。这是一种非常强大的文本搜索工具,它能使用特定模式匹配搜索文本(包括正则表达式),并且默认输出匹配行。
它的使用权限是所有用户。
GREP的工作方式是在一个或多个文件中搜索字符串模板。如果模板包括空格,那么就要被引用,模板后的所有字符串被看作文件名。搜索的结果被送到屏幕,不影响原文件内容。GREP的五个功能分别为:(1)多个文件查询 grep "sort" *.doc #见文件名的匹配。
(2)行匹配:输出匹配行的计数 grep -c "48" data.doc #输出文档中含有48字符的行数。(3)显示匹配行和行数 grep -n "48" data.doc #显示所有匹配48的行和行号。(4)显示非匹配的行 grep -vn "48" data.doc #输出所有不包含48的行。
(5)大小写敏感 grep -i "ab" data.doc #输出所有含有ab或Ab的字符串的行。扩展资料正则表达式,又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。
正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。
正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。正则表达式的特点是:1. 灵活性、逻辑性和功能性非常强。2. 可以迅速地用极简单的方式达到字符串的复杂控制。
3. 对于刚接触的人来说,比较晦涩难懂。由于正则表达式主要应用对象是文本,因此它在各种文本编辑器场合都有应用,小到著名编辑器EditPlus,大到Microsoft Word、Visual Studio等大型编辑器,都可以使用正则表达式来处理文本内容。
正则表达式:grep “^[[:space :]]*$” 表示什么?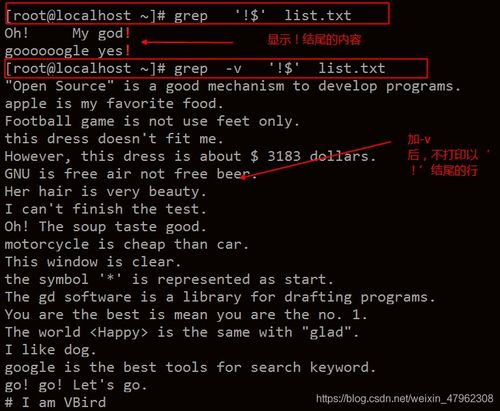
逐个进行解析如下:^: 表示字符串开始。[[:space :]] : 表示匹配空格。
*: 表任意字符。
[[:space :]]* : 表示任意个空格。$: 表示字符串结束。
正则表达式的符号
(摘自《正则表达式之道》)正则表达式 由一些普通字符和一些元字符(metacharacters)组成。普通字符包括大小写的字母和数字,而元字符则具有特殊的含义,我们下面会给予解释。
在最简单的情况下,一个正则表达式看上去就是一个普通的查找串。
例如,正则表达式testing中没有包含任何元字符,它可以匹配testing和testing123等字符串,但是不能匹配Testing。要想真正的用好正则表达式,正确的理解元字符是最重要的事情。下表列出了所有的元字符和对它们的一个简短的描述。 元字符 描述 \ 将下一个字符标记符、或一个向后引用、或一个八进制转义符。
例如,“\\n”匹配\n。“\n”匹配换行符。序列“\\”匹配“\”而“\(”则匹配“(”。
即相当于多种编程语言中都有的“转义字符”的概念。 ^ 匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。
$ 匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 * 匹配前面的子表达式任意次。
例如,zo*能匹配“z”,“zo”以及“zoo”,但是不匹配“bo”。*等价于{0,}。 + 匹配前面的子表达式一次或多次(大于等于1次)。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。
+等价于{1,}。 ? 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”中的“do”。?等价于{0,1}。
{n} n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 {n,} n是一个非负整数。
至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。
“o{0,}”则等价于“o*”。 {n,m} m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。
例如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 ? 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。
非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。 .点 匹配除“\r\n”之外的任何单个字符。
要匹配包括“\r\n”在内的任何字符,请使用像“[\s\S]”的模式。 (pattern) 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“\(”或“\)”。
(?:pattern) 非获取匹配,匹配pattern但不获取匹配结果,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分是很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。
(?=pattern) 非获取匹配,正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字�。
请问grep和正则表达式能不能只显示找到的匹配此表达式的字符?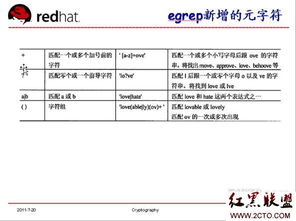
grep可以,加上参数-o,其可用的最好的正则表达式引擎是perl风格的,需要在命令行加参数-P笼统地说正则表达式没有意义,不同的语言利用正则表达式完成匹配后,想输出什么,和正则表达式已经没有关系了,完全看程序的逻辑,grep加上-o参数其实就是实现了“输出匹配”的逻辑。
grep正则表达式如何匹配固定字母和符号组合中的第一个字母部分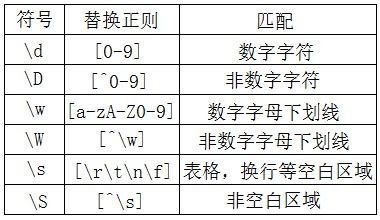
/^[
标签: grep正则表达式数字范围


